一. 最简单的HTTP服务器
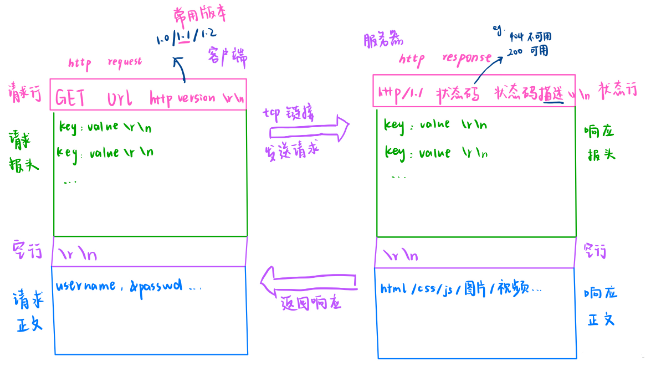
我们可以尝试实现一个简单的 HTTP 服务器,它可以接受客户端连接并返回一个 "Hello World" 网页。为了详细说明这段代码,让我们逐行进行解释。
#include <sys/socket.h> // 引入套接字相关的头文件 #include <netinet/in.h> // 引入处理IPv4地址的头文件 #include <arpa/inet.h> // 引入INET相关函数的头文件 #include <unistd.h> // 引入UNIX标准函数,如close() #include <stdio.h> // 引入标准输入输出头文件 #include <string.h> // 引入字符串处理函数的头文件 #include <stdlib.h> // 引入标准库函数,如atoi()
这些头文件包含了程序所需的各种函数和类型:
sys/socket.h: 提供套接字函数和数据结构。
netinet/in.h: 提供了用于处理 IPv4 地址的结构和函数。
arpa/inet.h: 提供了用于操作 IP 地址的函数,如 inet_addr。
unistd.h: 提供了 UNIX 标准函数,如 close。
stdlib.h: 提供了一些标准库函数,如 atoi。
void Usage() {
printf("usage: ./server [ip] [port]\n");
}定义了一个 Usage 函数,该函数打印使用说明,说明程序需要两个命令行参数,即 IP 地址和端口号。
int main(int argc, char* argv[]) {程序的 main 函数开始。
if (argc != 3) {
Usage();
return 1;
}
检查命令行参数的数量。如果参数数量不等于 3(程序名、IP 地址和端口号)
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd < 0) {
perror("socket"); // 如果创建失败,打印错误信息
return 1;
}创建一个套接字。AF_INET 表示使用 IPv4,SOCK_STREAM 表示使用 TCP。
struct sockaddr_in addr; // 定义一个地址结构体 addr.sin_family = AF_INET; // 设置为IPv4地址族 addr.sin_addr.s_addr = inet_addr(argv[1]); // 设置IP地址 addr.sin_port = htons(atoi(argv[2])); // 设置端口号,并转换为网络字节序
设置服务器端地址:
sin_family:家族类型为AF_INET,即 IPv4。sin_addr.s_addr:将命令行参数中的 IP 地址转化为网络字节序的二进制地址。sin_port:将命令行参数中的端口号转化为网络字节序的端口号。
int ret = bind(fd, (struct sockaddr*)&addr, sizeof(addr));
if (ret < 0) {
perror("bind"); // 如果绑定失败,打印错误信息
return 1;
}将套接字绑定到指定的 IP 地址和端口。
ret = listen(fd, 10);
if (ret < 0) {
perror("listen"); // 如果监听失败,打印错误信息
return 1;
}开始监听连接,允许最多 10 个连接等待队列。
for (;;) {
struct sockaddr_in client_addr; // 定义客户端地址结构体
socklen_t len = sizeof(client_addr); // 定义长度变量
int client_fd = accept(fd, (struct sockaddr*)&client_addr, &len);
if (client_fd < 0) {
perror("accept"); // 如果接受连接失败,打印错误信息
continue; // 继续下一次循环
}进入一个无限循环,持续接受客户端的连接:
client_addr:用于存储客户端的地址。
len:保存地址client_addr的长度。accept:接受一个客户端连接。
如果 accept 失败,打印错误信息并继续下一次循环。
char input_buf[1024 * 10] = {0};
ssize_t read_size = read(client_fd, input_buf, sizeof(input_buf) - 1);
if (read_size < 0) {
perror("read"); // 如果读取失败,打印错误信息
close(client_fd); // 关闭客户端套接字
continue; // 继续下一次循环
}
printf("[Request] %s\n", input_buf);定义一个缓冲区并读取客户端数据:
input_buf:存储从客户端读取的数据。read:从客户端套接字读取数据至缓冲区。
如果读取失败,打印错误信息,关闭客户端套接字,并继续下一次循环。
char buf[1024] = {0};
const char* hello = "<h1>hello world</h1>";
sprintf(buf, "HTTP/1.0 200 OK\nContent-Length:%lu\n\n%s", strlen(hello), hello);
write(client_fd, buf, strlen(buf));定义一个缓冲区并发送响应:
hello:要发送的 HTML 内容。sprintf:格式化 HTTP 响应,包括头部和内容。write:将响应发送回客户端。
close(client_fd); // 关闭客户端套接字 }
关闭客户端连接。
close(fd); // 关闭服务器套接字 return 0; // 正常退出 }
关闭服务器套接字并正常退出程序。
总结:
该程序是一个基本的 HTTP 服务器,负责监听指定的 IP 地址和端口,接受客户端连接,读取请求并发送一个包含 "Hello World" 的 HTML 响应。它通过使用 UNIX 系统调用(如 socket、bind、listen 和 accept 等)来实现这一功能。
完整代码:
#include <sys/socket.h> // 引入套接字相关的头文件
#include <netinet/in.h> // 引入处理IPv4地址的头文件
#include <arpa/inet.h> // 引入INET相关函数的头文件
#include <unistd.h> // 引入UNIX标准函数,如close()
#include <stdio.h> // 引入标准输入输出头文件
#include <string.h> // 引入字符串处理函数的头文件
#include <stdlib.h> // 引入标准库函数,如atoi()
// 打印服务器的使用方法
void Usage() {
printf("usage: ./server [ip] [port]\n");
}
int main(int argc, char* argv[]) {
// 确保命令行参数数量正确(应为3个:程序名、IP地址和端口号)
if (argc != 3) {
Usage();
return 1;
}
// 创建一个基于IPv4的TCP套接字
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd < 0) {
perror("socket"); // 如果创建失败,打印错误信息
return 1;
}
struct sockaddr_in addr; // 定义一个地址结构体
addr.sin_family = AF_INET; // 设置为IPv4地址族
addr.sin_addr.s_addr = inet_addr(argv[1]); // 设置IP地址
addr.sin_port = htons(atoi(argv[2])); // 设置端口号,并转换为网络字节序
// 将套接字绑定到指定的IP地址和端口
int ret = bind(fd, (struct sockaddr*)&addr, sizeof(addr));
if (ret < 0) {
perror("bind"); // 如果绑定失败,打印错误信息
return 1;
}
// 开始监听传入的连接,允许最多10个连接同时等待
ret = listen(fd, 10);
if (ret < 0) {
perror("listen"); // 如果监听失败,打印错误信息
return 1;
}
// 无限循环,持续接受客户端的连接
for (;;) {
struct sockaddr_in client_addr; // 定义客户端地址结构体
socklen_t len = sizeof(client_addr); // 定义长度变量
// 接受一个客户端连接,并将客户端的地址信息存储在client_addr中
int client_fd = accept(fd, (struct sockaddr*)&client_addr, &len);
if (client_fd < 0) {
perror("accept"); // 如果接受连接失败,打印错误信息
continue; // 继续下一次循环
}
// 定义一个缓冲区,用于存储从客户端读取的数据
char input_buf[1024 * 10] = {0};
// 从客户端读取数据,最多读取缓冲区大小-1字节
ssize_t read_size = read(client_fd, input_buf, sizeof(input_buf) - 1);
if (read_size < 0) {
perror("read"); // 如果读取失败,打印错误信息
close(client_fd); // 关闭客户端套接字
continue; // 继续下一次循环
}
// 打印接收到的请求
printf("[Request] %s\n", input_buf);
// 定义一个缓冲区,用于存储响应数据
char buf[1024] = {0};
// 定义要发送的HTML内容
const char* hello = "<h1>hello world</h1>";
// 格式化HTTP响应消息,包括HTTP头部和HTML内容
sprintf(buf, "HTTP/1.0 200 OK\nContent-Length:%lu\n\n%s", strlen(hello), hello);
// 将响应消息发送回客户端
write(client_fd, buf, strlen(buf));
// 关闭客户端套接字
close(client_fd);
}
// 关闭服务器套接字
close(fd);
return 0; // 正常退出
}二.服务器 2.0
Protocol.hpp
#pragma once
#include <iostream>
#include <string>
using namespace std;
//客户端
class httpRequest
{
public:
httpRequest(){};
~httpRequest(){};
public:
string inbuffer;//缓冲区
//简单一点主要看一下http的细节
// string reqline;//请求行
// vector<std::string> reqheader;//报头
// string body;//请求正文
//第一行细分
// string method;
// string url;
// string httpversion;
};
//服务器
class httpResponse
{
public:
string outbuffer;//缓冲区
};httpserver.hpp httpServer.hpp
#pragma once
// 确保头文件只被包含一次
#include "Protocol.hpp"
// 包含自定义的协议处理头文件,可能定义了 httpRequest 和 httpResponse 类
#include <iostream>
#include <string>
#include <stdlib.h>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <sys/wait.h>
#include <signal.h>
#include <functional>
using namespace std;
// 定义错误码枚举
enum {
USAGG_ERR = 1, // 使用错误
SOCKET_ERR, // 套接字创建错误
BIND_ERR, // 绑定错误
LISTEN_ERR // 监听错误
};
const int backlog = 5;
// 定义监听队列的最大长度
// 定义函数类型别名,用于处理HTTP请求和响应的回调函数
typedef function<void(const httpRequest&, httpResponse&)> func_t;
// 处理HTTP请求的函数
void handlerEntery(int sock,func_t callback)
{
// 1. 读到完整的http请求
// 2. 反序列化
// 3. httprequst, httpresponse, callback(req, resp)
// 4. resp序列化
// 5. send
char buffer[4096];
httpRequest req;
httpResponse resp;
ssize_t n=recv(sock,buffer,sizeof(buffer)-1,0);//大概率我们直接就能读取到完整的http请求
if(n>0)
{
buffer[n]=0;
req.inbuffer=buffer;
callback(req,resp);
send(sock,resp.outbuffer.c_str(),resp.outbuffer.size(),0);
}
}
// HTTP服务器类
class httpServer {
public:
// 构造函数,初始化端口号和监听套接字
httpServer(const uint16_t port) : _port(port), _listensock(-1) {}
// 初始化服务器
void initServer() {
// 创建套接字
_listensock = socket(AF_INET, SOCK_STREAM, 0);
if (_listensock < 0) {
exit(SOCKET_ERR); // 如果创建失败,退出程序
}
// 绑定套接字到本地地址和端口
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = INADDR_ANY; // 绑定到任意地址
if (bind(_listensock, (struct sockaddr *)&local, sizeof(local)) < 0) {
exit(BIND_ERR); // 如果绑定失败,退出程序
}
// 设置套接字为监听状态
if (listen(_listensock, backlog) < 0) { // 设置监听队列长度
exit(LISTEN_ERR); // 如果监听失败,退出程序
}
}
// 启动服务器,处理请求
void start(func_t func) {
// 忽略子进程结束的信号
signal(SIGCHLD, SIG_IGN);
for (;;) { // 无限循环,等待连接
// 接受新连接
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int sock = accept(_listensock, (struct sockaddr *)&peer, &len);
if (sock < 0) {
continue; // 如果接受失败,继续下一次循环
}
// 创建子进程处理连接
int fd = fork();
if (fd == 0) {
close(_listensock); // 子进程关闭监听套接字
handlerEntery(sock, func); // 处理HTTP请求
close(sock); // 处理完毕后关闭连接套接字
exit(0); // 子进程退出
}
close(sock); // 父进程关闭连接套接字
}
}
// 析构函数
~httpServer() {
// 可以在这里进行资源清理
}
private:
uint16_t _port; // 服务器监听的端口号
int _listensock; // 监听套接字的文件描述符
};⭕ 如何理解这个地方子进程的退出和关闭?
在 start 函数中,服务器通过 fork() 系统调用创建子进程来处理每个新的连接。以下是对子进程退出和关闭操作的详细解释:
子进程的创建和退出
1.创建子进程:
int fd = fork();: 这行代码是创建子进程的关键。fork()调用会创建一个新的子进程。在父进程中,fork()返回子进程的进程ID;在子进程中,fork()返回0。
1.在子进程中
close(_listensock);: 子进程不需要监听新的连接,因此它关闭监听套接字。这是因为监听套接字由父进程负责,并且所有子进程都会继承父进程的文件描述符。
handlerEntery(sock, func);: 子进程调用 handlerEntery 函数来处理HTTP请求。这个函数会读取请求、反序列化、调用回调函数处理请求、序列化响应并发送响应。
close(sock);: 在处理完请求并发送响应后,子进程关闭与客户端的连接套接字,因为它不再需要这个套接字。
exit(0);: 子进程通过 exit(0) 退出。这个调用会导致子进程终止,并且操作系统会回收子进程占用的所有资源。
子进程退出的意义.
资源回收: 当子进程退出时,操作系统会自动回收子进程所占用的所有资源,包括打开的文件描述符、内存等。这是非常重要的,因为如果不回收资源,可能会导致资源泄漏。
避免僵尸进程: 在调用 fork() 之前,父进程通过 signal(SIGCHLD, SIG_IGN); 忽略了 SIGCHLD 信号。这意味着当子进程结束时,父进程不会收到通知,操作系统会自动清理掉子进程,防止产生僵尸进程。
父进程关闭连接套接字
close(sock);: 在父进程中,fork() 返回的是子进程的ID,因此父进程不会进入 if (fd == 0) 块。父进程也不需要这个与客户端的连接套接字,因为它只负责监听新的连接,所以它关闭这个套接字。
总结来说,子进程的退出和关闭操作确保了每个HTTP请求都能被单独的子进程处理,并且在处理完成后,子进程能够干净地退出,不会留下僵尸进程或资源泄漏。父进程继续监听新的连接请求,而子进程则负责处理已经接受的连接。
httpServer.cc
#include "httpServer.hpp"
#include <memory>
// 打印程序使用方法的函数
void Usage(const string& proc) {
cout << "\nUsage:\n\t" << proc << " local_port\n\n";
}
// 处理HTTP GET请求的函数,参数为请求和响应对象
void Get(const httpRequest &req, httpResponse &resp)
{
cout << "----------------http start---------------" << endl;
cout << req.inbuffer << endl;
cout << "----------------http end-----------------" << endl;
string respline = "HTTP/1.1 200 OK\r\n";
// string respheader;
string respblank = "\r\n";
//随便做一个网页
string body="<html lang=\"en\"><head><meta charset=\"UTF-8\"><title>for test</title><h1>hello world</h1></head><body><p>你好呀 祝你天天开心~</p></body></html>";
//序列化
resp.outbuffer += respline;
resp.outbuffer += respblank;
resp.outbuffer += body;
}
// 程序入口点
int main(int argc, char* argv[]) {
// 检查命令行参数数 量是否正确
if (argc != 2) {
// 如果参数数量不正确,显示使用方法并退出
Usage(argv[0]);
exit(USAGG_ERR); // 假设 USAGG_ERR 是一个定义的错误代码
}
// 将命令行参数转换为端口号
uint16_t serverport = static_cast<uint16_t>(atoi(argv[1]));
// 使用智能指针创建httpServer实例,自动管理内存
std::unique_ptr<httpServer> server(new httpServer(serverport));
// 初始化服务器
server->initServer();
// 启动服务器,并传入Get函数作为处理HTTP请求的回调
server->start(Get);
// 程序正常结束
return 0;
}⭕ 解释argc 和argv的设计与运用
在C和C++程序中,argc 和 argv 是 main 函数的两个参数,它们用于处理命令行参数。
argc (argument count)
argc 是一个整数,代表传递给程序的命令行参数的数量。它至少总是为1,因为 argv[0] 总是包含程序的名称或路径。
argv (argument vector)
argv 是一个指向字符指针的指针,它指向一个字符串数组,这些字符串包含了程序的命令行参数。argv[0] 是程序的名称或路径,argv[1] 是第一个命令行参数,依此类推。
以下是 argc 和 argv 在上述代码中的设计与运用:
1.程序入口点:
int main(int argc, char* argv[]) {这里 main 函数接收 argc 和 argv 作为参数。
1.检查参数数量:
if (argc != 2) {程序期望用户输入一个命令行参数,即端口号。如果 argc 不等于2(程序名称和一个参数),则说明用户没有正确输入参数。
1.打印使用方法:
Usage(argv[0]);
如果参数数量不正确,程序调用 Usage 函数,并传递 argv[0] 作为参数,这通常是程序的名称。Usage 函数会打印出如何正确使用程序的信息。
1.获取端口号:
uint16_t serverport = static_cast<uint16_t>(atoi(argv[1]));
程序将 argv[1](第一个命令行参数,即用户输入的端口号字符串)转换为整数,并将其存储在 serverport 变量中。
启动服务器:
程序使用 serverport 来初始化和启动 httpServer 实例。
通过这种方式,argc 和 argv 提供了一种灵活的方式来从命令行接收用户输入,使得程序可以根据不同的输入执行不同的操作。在上述代码中,它们用于指定HTTP服务器监听的端口号。如果用户没有提供正确的参数,程序会提示正确的使用方法并退出。
我们发现udp、tcp、http所有的底层逻辑都是差不多的,而我们只要写上层逻辑就好了。
这里我们主要说原理,下面1-5的工作我们都不做了,所以httpRequest,httpResponse也都给一个缓冲区就行了。
callback 的是 Get 函数
下面我们用浏览器充当客户端发起请求看一下结果
无法访问,我们来开放一下端口号,腾讯云可以直接在小程序上开,就还挺方便的~

然后就可以看到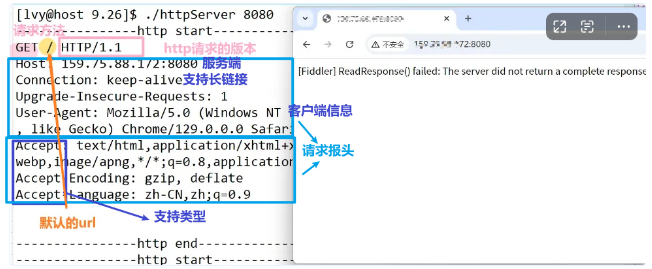
报头我们暂时不要后面慢慢填,正文部分我们搞一个网页。
网页不会写,可以搜一下w3cschool html教程
这里我们先写到Get函数里,后面我们在分离
void Get(const httpRequest &req, httpResponse &resp)
{
cout << "----------------http start---------------" << endl;
cout << req.inbuffer << endl;
cout << "----------------http end-----------------" << endl;
string respline = "HTTP/1.1 200 OK\r\n";
// string respheader;
string respblank = "\r\n";
//随便做一个网页
string body="<html lang=\"en\"><head><meta charset=\"UTF-8\"><title>for test</title><h1>hello world</h1></head><body><p>你好呀 祝你天天开心~</p></body></html>";
//序列化
resp.outbuffer += respline;
resp.outbuffer += respblank;
resp.outbuffer += body;
}虽然我们在响应的时候没有带响应报头,但是我们的浏览器依旧是能识别的,这里想说的是现在浏览器很智能了,可以不用告诉它正文是什么也可以根据正文内容识别这是什么东西,但是有的浏览器做不到。这里我们用的是chrome浏览器。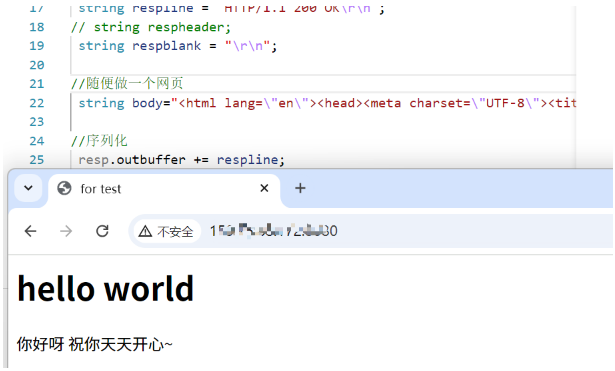
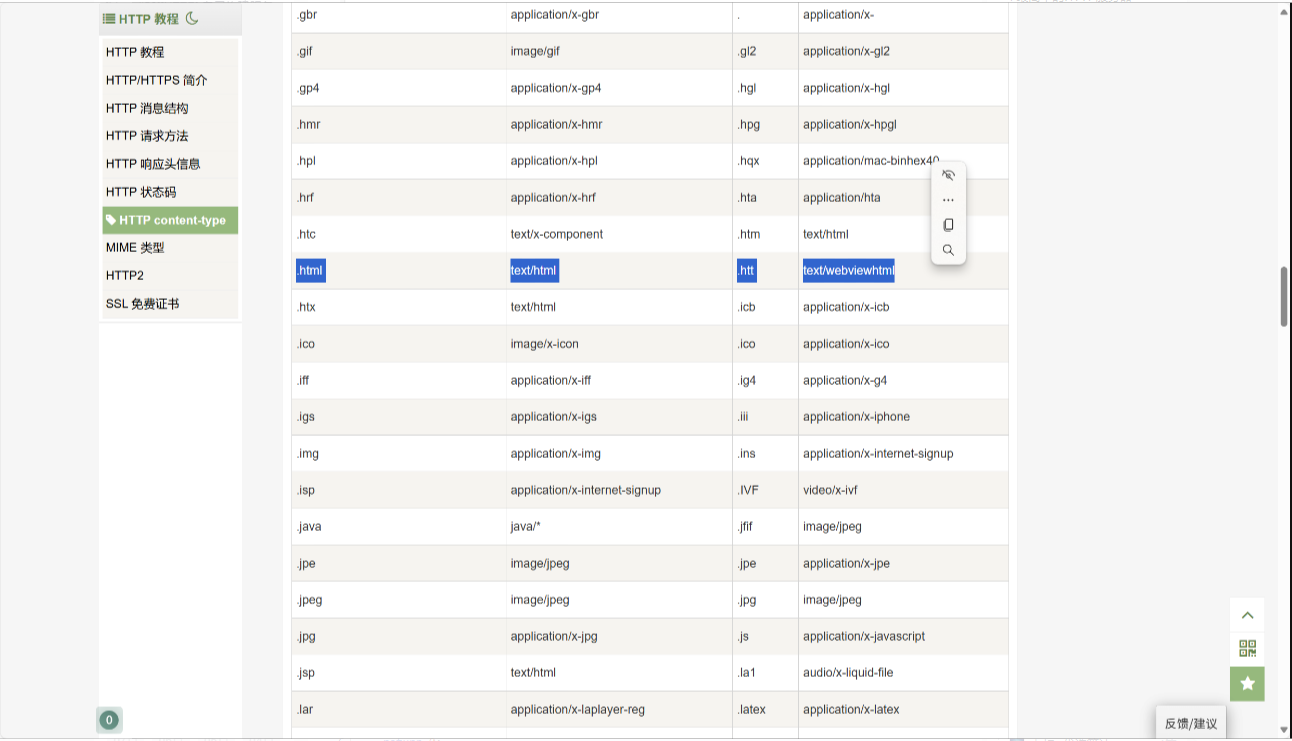
如果我们要加一个报头里面可以带一些属性呢?
如Content-Type ,告诉别人返回的是什么资源。网上可以搜一下Content-Type 对照表,来进行添加
三.服务器和网页分离
简单实现之后,我们来解决服务器和网页分离,然后通过服务器把网页返回
引入:
在C++中,istringstream 类是在 <sstream> 头文件中定义的,所以你需要包含这个头文件来使用 istringstream 对象。下面是如何在代码中包含它的示例:
#include <sstream>
int main() {
std::string line = "一些文本";
std::istringstream iss(line);
// ... 使用 iss ...
return 0;
}在这个例子中,istringstream 被用来从字符串 line 中读取数据,就像从文件中读取一样。
运用更新:
#pragma once
#include <iostream>
#include <string>
#include <sstream>
using namespace std;
class Util
{
public:
// xxx yyy zzz\r\naaa
static string GetOneline(string &buffer, const string &sep)
{
auto pos = buffer.find(sep);
if (pos == string::npos)
return "";
string sub = buffer.substr(0, pos);
return sub;
}
};
const string sep = "\r\n";//切割符
class httpRequest
{
public:
httpRequest(){};
~httpRequest(){};
void parse()
{
// 1. 从inbuffer中拿到第一行,分隔符\r\n
string line = Util::GetOneline(inbuffer, sep);
if (line.empty())
return;
// 2. 从请求行中提取三个字段
istringstream iss(line);
iss >> method >> url >> httpversion;
}
public:
string inbuffer;
// string reqline;
// vector<std::string> reqheader;
// string body;
string method;
string url;
string httpversion;
};
//服务器
class httpResponse
{
public:
string outbuffer;//缓冲区
};#pragma once
#include <iostream>
#include <string>
using namespace std;
class Util
{
public:
// xxx yyy zzz\r\naaa
static string GetOneline(string &buffer, const string &sep)
{
auto pos = buffer.find(sep);
if (pos == string::npos)
return "";
string sub = buffer.substr(0, pos);
return sub;
}
};什么是web根目录?
实际上未来一个web服务器写好之后,可不仅仅有这些代码。每一个web服务器都有web根目录,未来所有图片、视频、音频等各种web资源都在这个目录下,按照目录结构组织号好,未来想请求资源就从url请求。那如何保证按照我们的需求在指定路径下去寻找呢?
设计如下目录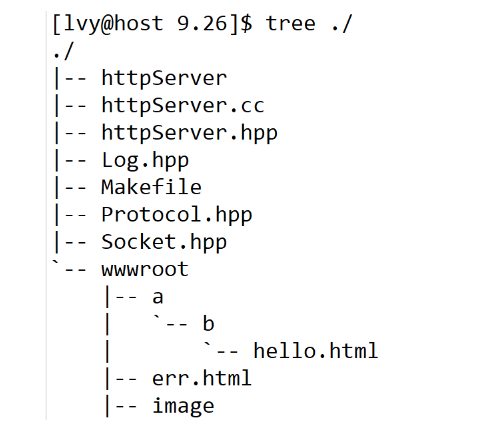
err.html
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<title>404 Not Found</title>
<style>
body {
text-align: center;
padding: 150px;
}
h1 {
font-size: 50px;
}
body {
font-size: 20px;
}
a {
color: #008080;
text-decoration: none;
}
a:hover {
color: #005F5F;
text-decoration: underline;
}
</style>
</head>
<body>
<div>
<h1>404</h1>
<p>页面未找到<br></p>
<p>
您请求的页面可能已经被删除、更名或者您输入的网址有误。<br>
请尝试使用以下链接或者自行搜索:<br><br>
<a href="https://www.baidu.com">百度一下></a>
</p>
</div>
</body>
</html>index.html:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <!-- <form action="/a/b/hello.html" method="post"> name: <input type="text" name="name"><br> password: <input type="password" name="passwd"><br> <input type="submit" value="提交"> </form> --> <h1>这个是我们的首页</h1> <!-- <img src="/image/1.png" alt="这是一直猫" width="100" height="100"> 根据src向我们的服务器浏览器自动发起二次请求 --> <!-- <img src="/image/2.jpg" alt="这是花"> --> </body> </html>
实现分离: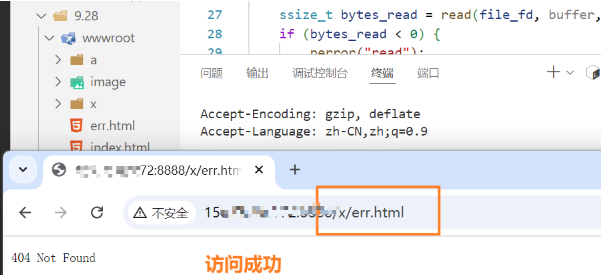
现在我们给网页添加一下功能,比如说网页是支持点击然后跳转链接的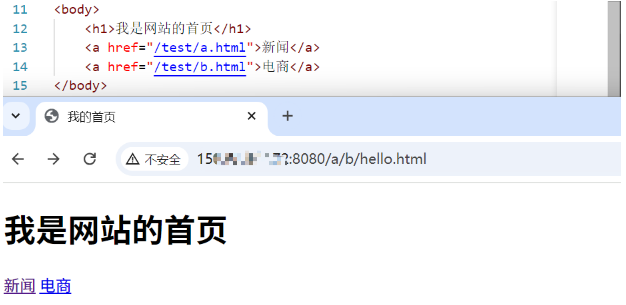
跳转成功啦~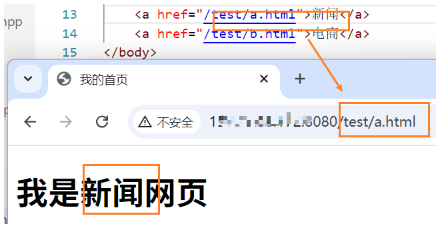
思考与补充:
1.请求和响应怎么保证应用层完整读取完毕了呢?
首先我们发现http请求都是字符串按行为单位,所以
我可以读取完整的一行
while(读取完整一行) --> 所有的请求行+请求行报文全部读完 --> 直到空行!
我们没说正文也是按行为单位分开的没有办法保证把正文读完,但是我们能保证把报头读完,而报头里有一个Content-Length:xxx(代表正文长度)
解析出来内容长度,在根据内容长度,读取正文即可!
2.请求和响应是怎么做到序列化和反序列化的?
http是用的特殊字符自己实现的。http序列化什么都不做直接发就好了,反序列化 :第一行+请求/响应报头,只要按照\r\n将字符串1->n即可!不用借助任何东西如Json
protobuf等。而正文序列化反序列也不用做直接发送就行了。如果你的正文携带结构化数据就要自己处理了。
上面我们也通过写代码的方式,验证上面说的东西。
以前写udp和tcp我们都写过服务端用过套接字,这里还是直接拿过来用啦
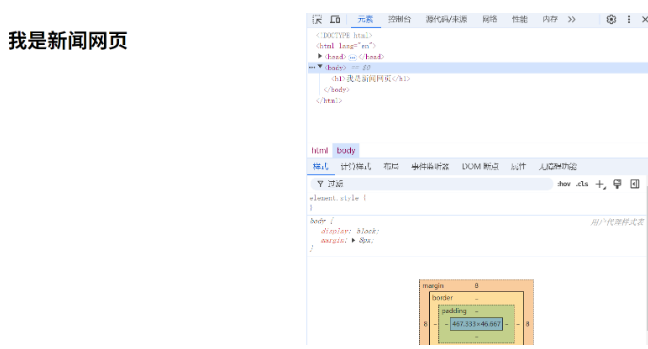
3. 如何监视查看网页端
按图片操纵即可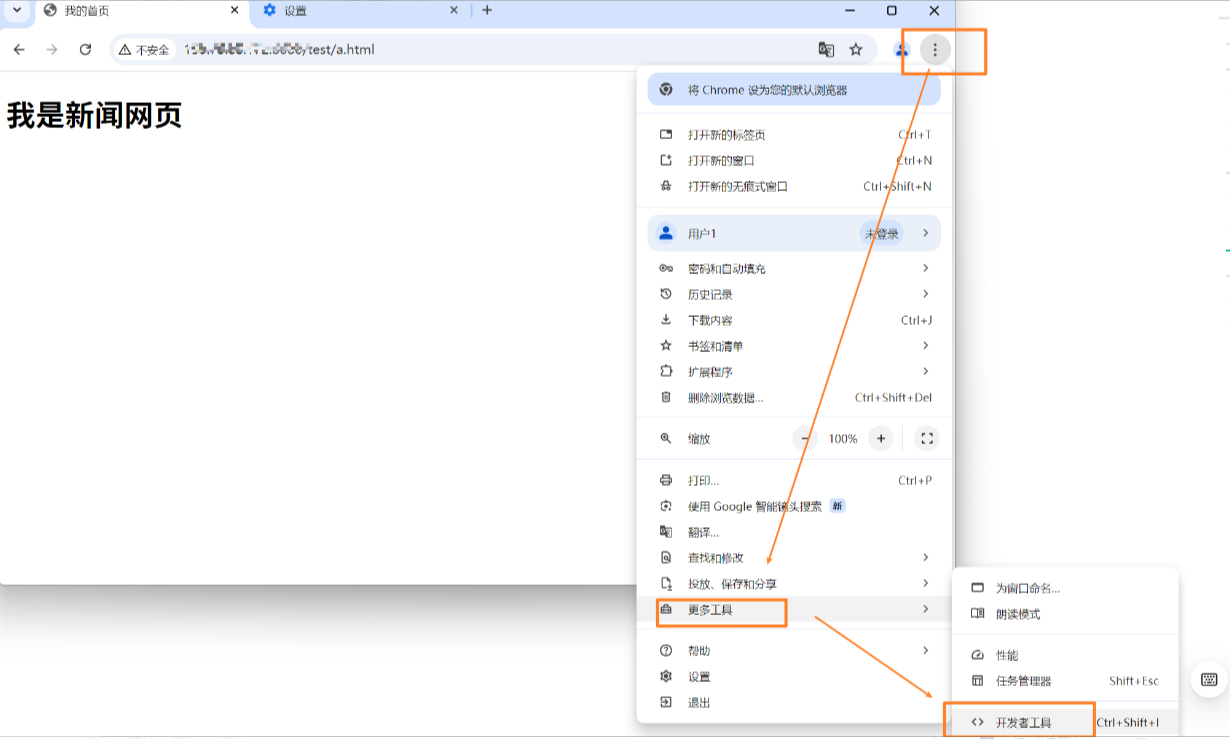
就可以查看到啦
本文链接:https://blog.runxinyun.com/post/293.html 转载需授权!














留言0